In the previous blog post, we covered the automated steps to create a VarSeq project. Today we will examine the active analysis steps. These are the steps that require human interpretation to analyze the clinically relevant variants. A lab tech can take the first pass at the output in the generated VarSeq project. They can perform the quality control and initial interpretation before passing the project off to the Lab Director or MD. The lab director will complete the summary and submit the finalized report.
Quality Control
There are two levels of quality control for the lab tech to perform, sample level, and variant and CNVs level. First, they should examine the samples, comparing the read depth and variant calling profiles across samples, and with previous historical runs. This information is in output from the Coverage Statistics and Sample Statistics algorithm. The Coverage Statistics algorithm provides percent coverage and mean coverage for the analysis target regions. Likewise, the Sample Statistics algorithm will provide per sample variant call rate. Together, this allows them to spot any samples with abnormal values. This may be indicative of errors in the sample collection or preparation.
After rerunning any samples that didn’t meet the quality control standards it’s time to dive into the variants and CNVs. Fortunately, VarSeq supports complex filter chains. This narrows our search based on overlapping genes or existing annotations, as well as on values from the variant caller. Relevant variant caller fields may include read depth, quality, and alt allele frequency. The lab tech should flag passing variants for interpretation if they have strong supporting evidence and are in a relevant region. For indels, this may mean looking at the variants plotted against the supporting reads from the BAM file in GenomeBrowse.
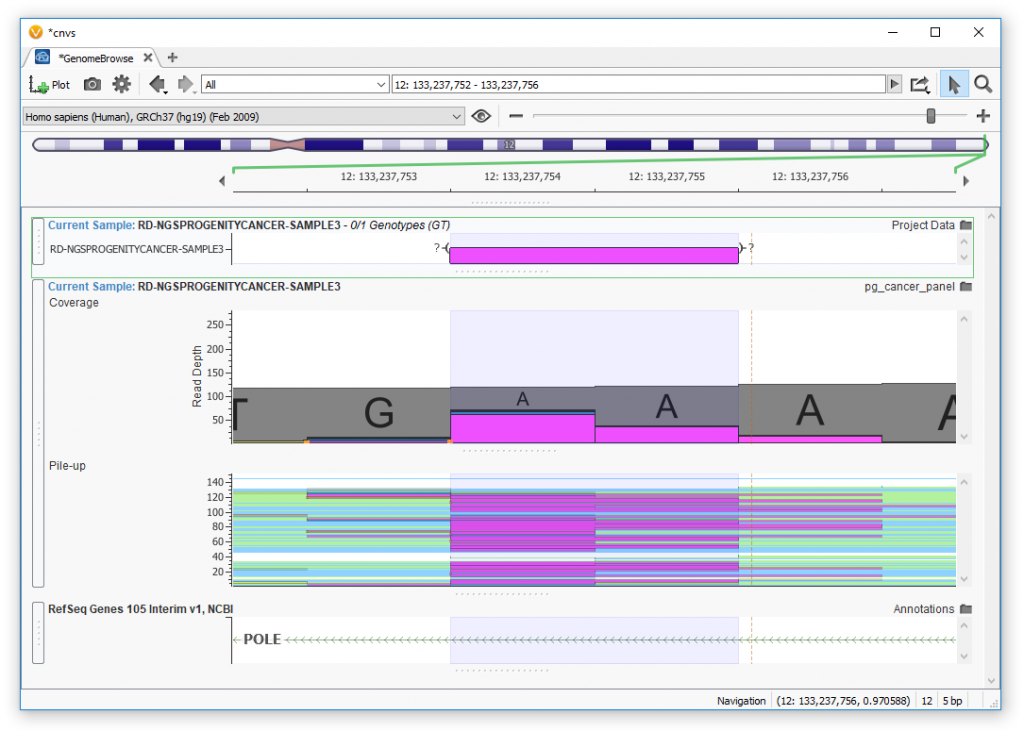
Likewise, we can plot CNVs. The p-value, average z-score, and average coverage values indicate the strength of the evidence. Additionally, CNV events that are flagged by the algorithm should be examined. The lab tech should flag each variant and CNV that meets the quality standards by adding it to a record set. This will make it easy to add the CNV to our report, as well as perform analyses with the ACMG workflow. To learn more about quality control for CNVs in VarSeq read about it here.
Interpretation
Once the lab tech has filtered down to just the quality variant and CNV events, they are ready to start the interpretation. For CNVs, they can begin by examining the annotations and regions they overlap. To learn more about the analysis tools available for CNVs check out this blog post. As the lab tech works through the CNVs, their interpretations are entered in a CNV Assessment Catalog. CNV Assessment Catalogs are a cornerstone of the CNV interpretation. First, they are used to pull interpretations into the report. Second, they allow the interpretation to be reused whenever the CNV is re-encountered.
After the CNVs have been interpreted, the next step is to analyze the variants with the ACMG workflow. Prior to going through the workflow we can use the automated ACMG algorithm to provide a preliminary classification. This preliminary classification prioritizes potentially pathogenic variants to interpret with the ACMG workflow.
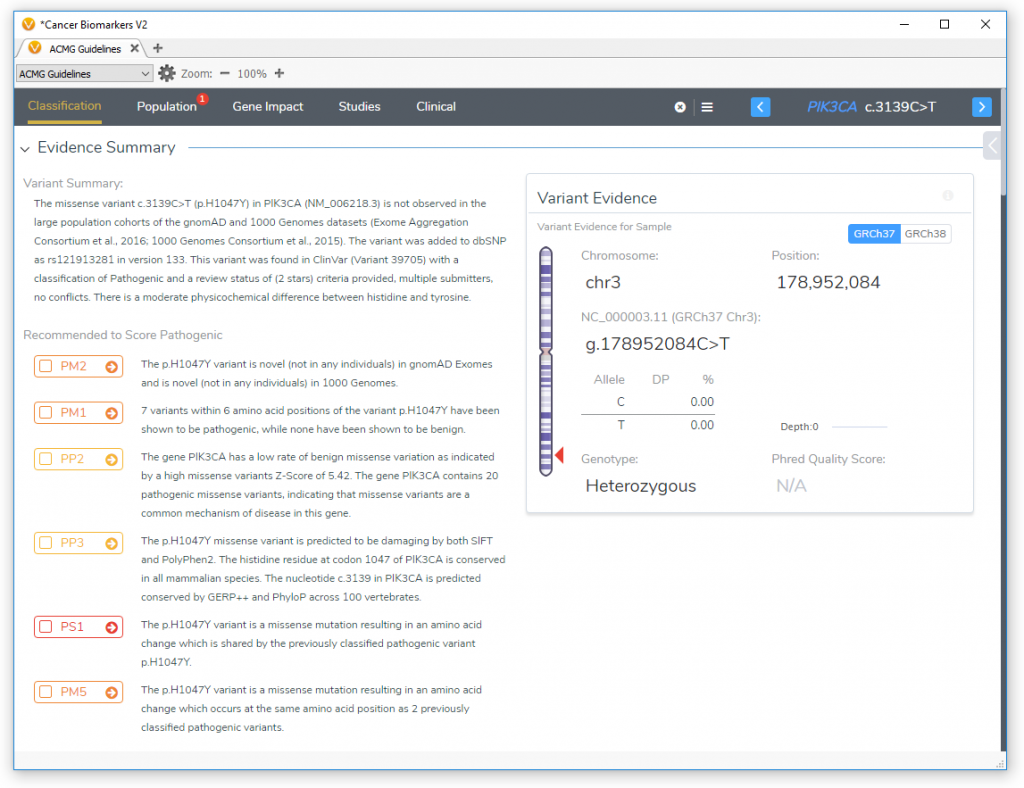
Validating and expanding upon the auto-classification is easy inside the ACMG workflow. The recommended classification criteria allow you to easily jump to the criteria for each variant. Each criteria provides all of the supporting information need to verify the recommendation and gather information for the interpretation. To learn more about the ACMG workflow and how it can be applied in VarSeq check out our series here. After the interpretations and assessments are complete the lab tech can generate a draft report.
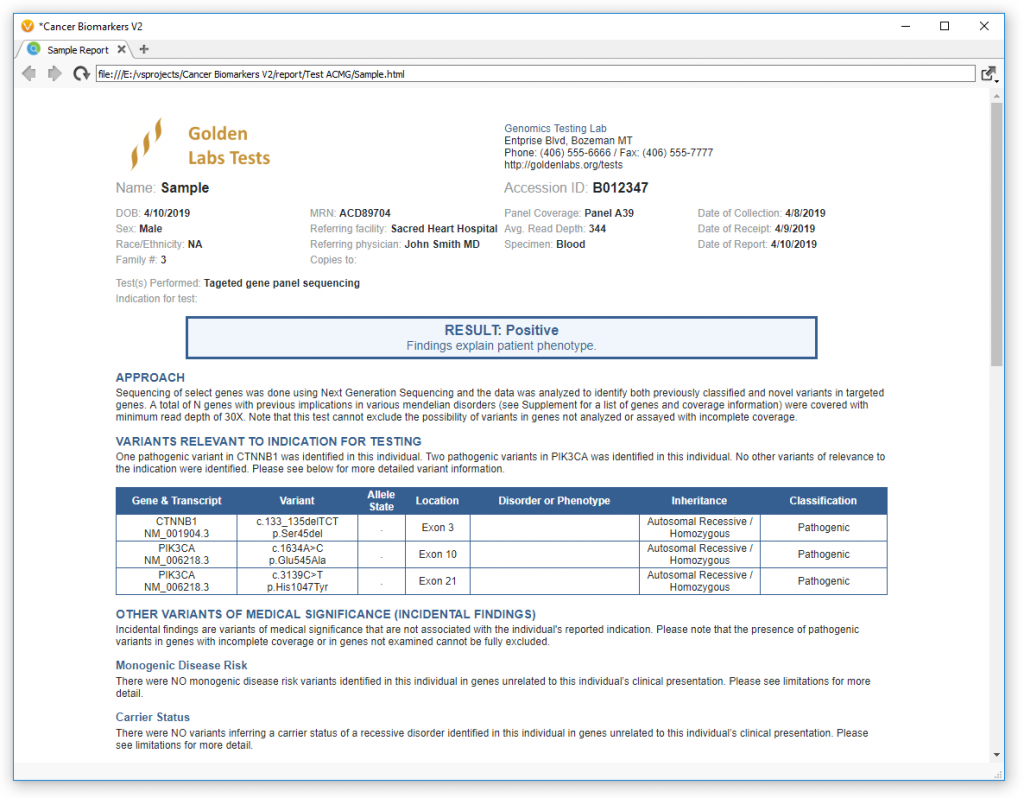
VarSeq reports populate automatically with the selected variants and CNVs. To do this, the report templates pull the information from the tables as well as from the saved interpretations. The last step for the lab tech is to add any additional sample information or corroborating evidence. After that, they can update the draft report and send it to the Lab Director or MD to review.
Review
At this point, most of the sample interpretation is already complete. The lab director just needs to review the included CNVs and variants, and their corresponding interpretations. If everything looks good they can fill in the report summary. The report summary may include the combined effects of the different variants and CNVs, as well as their associated phenotypes. Given the samples phenotype, the director may wish to provide clinical recommendations. Once this is complete the report is ready to be signed off and submitted to the medical records system. Continue on to the final post of this blog series, Automating Clinical Workflows: Part III.