Variant interpretation is an integral part of any workflow that results in some decisions being made about the validity and suspected functional impact of a variant in a given sample and their presenting phenotypes. The VarSeq Assessment Catalog functionality is designed to assist the VarSeq user in streamlining this process.
To include this functionality in your workflow, you will first create the Assessment Catalog framework to store the specific information you want to capture from each variant. From an open VarSeq project, go to View > Open > Assessment Catalog. Then select the option to “Create New Assessment Catalog”. Three database backends are supported, SQLite, PostgreSQL and MySQL.
For this example, I will choose the SQLite option and specify a local path to store the database file.
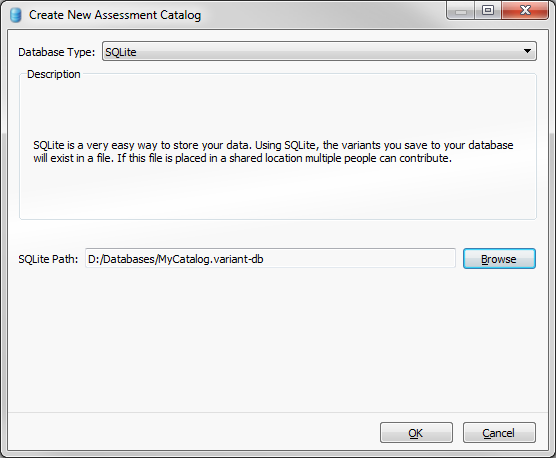
Figure 1: Creating new assessment catalog
In the next dialog, you will be asked to specify the schema used to define the expected fields in the catalog; there are a few predefined schemas in the “Select Schema” drop down list. For this example, I will select the predefined ACMG Classification options and then add some additional fields for reference.
The ACMG Classification schema contains two fields a Classification combo-box and then a multi-line text box for entering in notes. To add additional fields, click the plus sign along the right side of the dialog and set your options for the additional fields. The below example shows 3 additional fields including the name of the sample, name of the project and a validation check box.
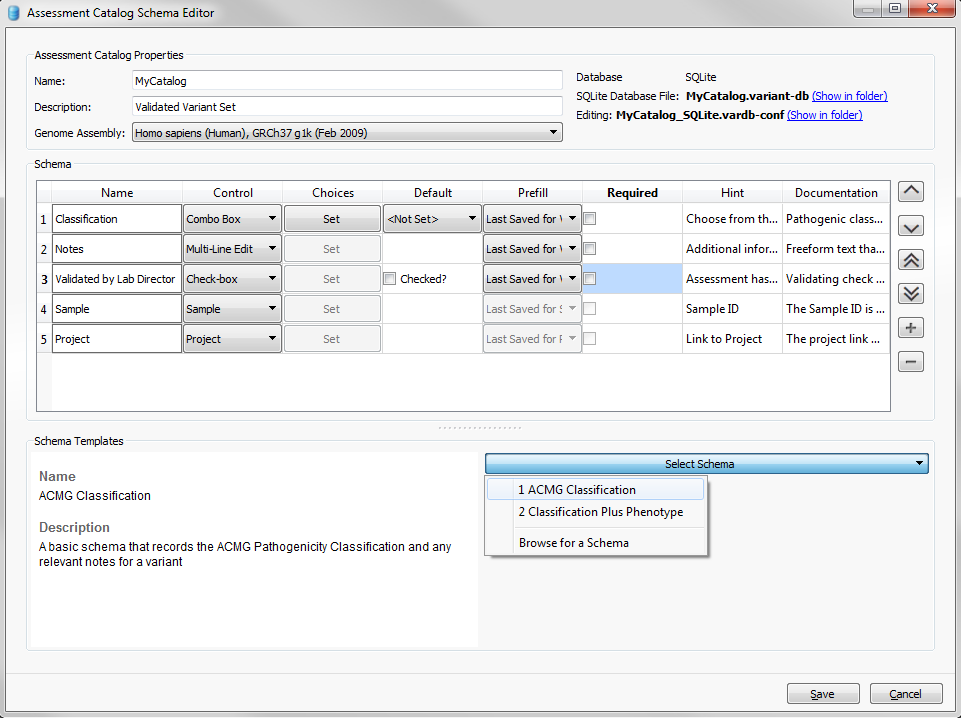
Figure 2: Catalog schema
Once the schema is saved it will open the catalog view in your VarSeq project, and as you scroll through your list of variants in the table you can add assessments for the variants in catalog view.
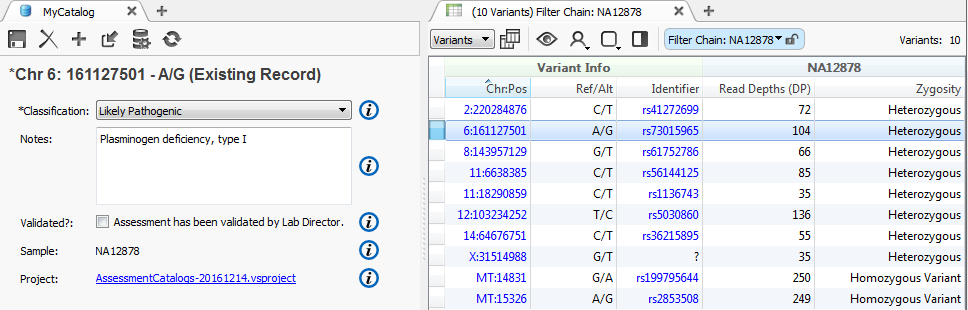
Figure 3: Adding assessment for variant
If at a later date you encounter the same variant and the assessment has changed, (for example now the classification is Likely Pathogenic instead of Pathogenic) you will see the following log under the current Recent Assessments list for that particular variant. At any time you can revert to a previous assessment for this record by clicking the “revert” button on any listed entry.
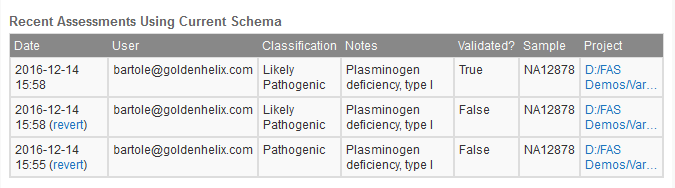
Figure 4: Assessment log
Adding variants as you encounter them is a great way to add new variant assessments, but what if you have a list of known variant assessments from legacy samples that you want to use to populate your catalog? How would you go about adding those assessments?
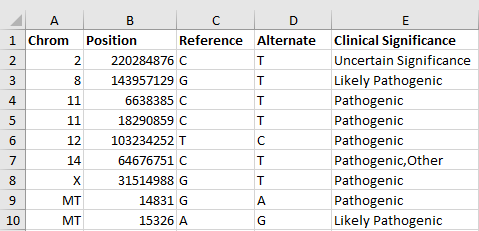
Figure 5: List of known variant assessments
The Import Variants to Assessment Catalog functionality makes it very easy to add in a list of known assessments.
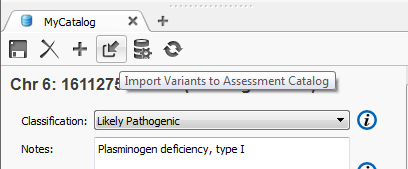
Figure 6: Import options for catalog
The import dialog will take a wide variety of supported file types like delimited text, VCF or BED. As long as the data in the file can be mapped to existing fields in the catalog, you should be good to go.
The variant list below (Figure 5) was saved as a delimited text file called “variantList.txt” and the following options were selected to import the data.
Figure 7: Select delimited text file
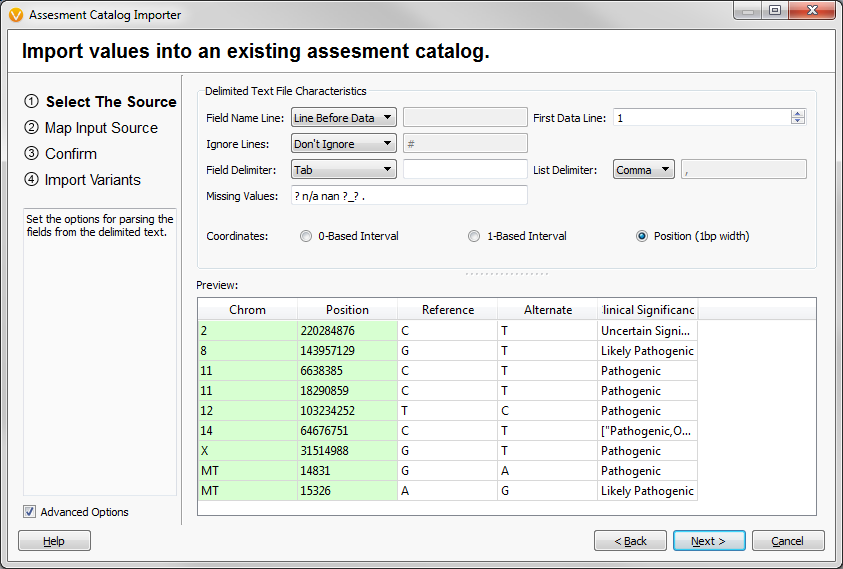
Figure 8: Specify chromosome and position fields
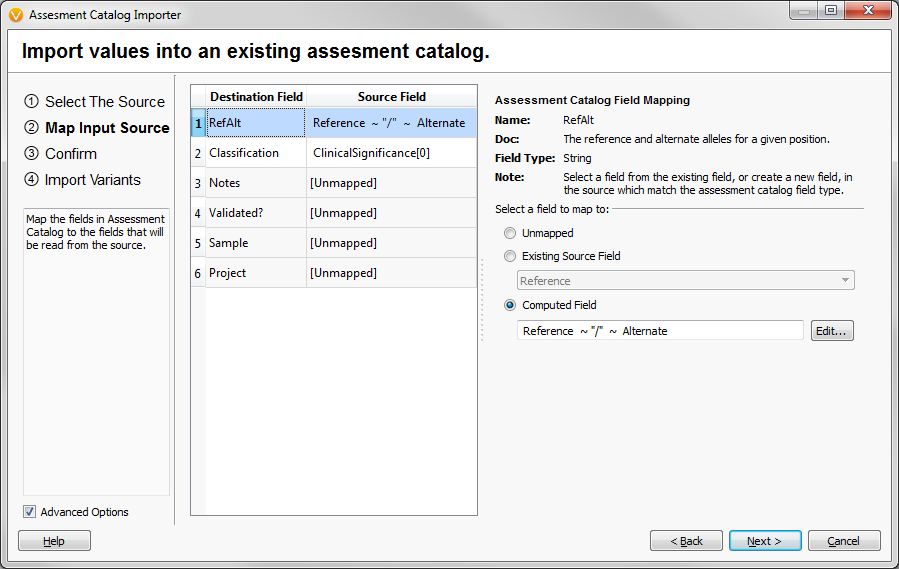
Figure 9: Map fields from the file to the catalog
The created catalogs can be integrated into your standard annotation and filtering workflow to ensure you don’t miss previously assessed variants in future samples. The catalog will appear as any other annotation source and can be added to a project by going to Add > Annotation and selecting the catalog from your Local > Assessment Catalog location. After annotation is complete you will see column groups added to your variant table with the fields specified in your catalog.
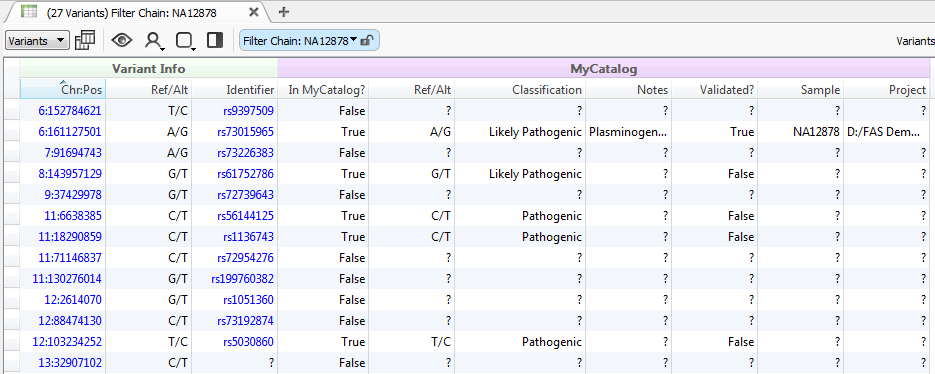
Figure 10: Catalog annotations
If any changes are made to the catalog, VarSeq will provide a notification in the project that the catalog is now out of data and prompt you to update your annotations.
As always if you have any questions or would like assistance in creating or using the VarSeq Assessment Catalog functionality please email us at support@goldenhelix.com.