CIViC
The Clinical Interpretations of Variants in Cancer, better known as CIViC, is an open access open source, community-driven web resource available to all VarSeq users. Nature Genetics published an article that states, “CIViC accepts public knowledge contributions but requires that experts review these submissions”. Fundamentally, the focus behind CIViC is to make sure the variants contained in the database go under the intense scrutiny of experts to be the highest quality. Our efforts in data curation follow CIViCs efforts to provide an interface designed to help keep variant interpretations current and comprehensive. The number of fields accessible from CIViC is pretty extensive in VarSeq, and some unique fields available in VarSeq can be seen in Figure 1.
In addition to providing gene, variant, disease, drug, and publication information, CIViC also reports clinical interpretations that are captured and displayed as evidence records consisting of a freeform ‘evidence statement’ and several other structured attributes. Each evidence record is associated with a specific gene, variant, disease and clinical action.

Fig 1: View of CIViC data from VarSeq table view.
Let’s break down the contents of each column pictured in Figure 1.
CIViC Evidence ID: simple ID given to evidence interpretation
Evidence Type: The following are four categories that groups each variant with the form of supporting evidence.
- Predictive: defined as the variant’s effect on therapeutic response
- Prognostic: variant’s impact on disease progression
- Predisposing: variants role in conferring susceptibility to a disease
- Diagnostic: variant’s impact on patient diagnosis
Clinical Significance:
- Sensitivity: Associated with positive response to treatment
- Poor/Better Outcome: Worse or better than expected clinical outcome
- Pathogenic: strong evidence variant is pathogenic
- Positive: Associated with diagnosis of disease
- Resistance/non-response: associated with negative treatment response
Evidence Direction: Supports – the experiment or study supports this variant’s response to drug
Evidence Level:
A: Proven/consensus association in human medicine
B: Clinical trial or other primary patient data supports association
C: Individual case reports from clinical journals
D: In vivo or in vitro models support association
E: Indirect evidence
Evidence Statement: Brief abstract of study results with protein/drug effects
Trust Rating: Strength of evidence with respected academic standing and reproducibility of experiment’s results and supporting evidence with differing methods. (0 stars-poor rating to 5 star-excellent rating)
COSMIC 71
The supporting evidence data provided in CIViC can provide even more clarity when coupled with COSMIC’s dense collection of somatic variant information. The Catalogue Of Somatic Mutations In Cancer (COSMIC) combines curation of the scientific literature with tumor resequencing data from the Cancer Genome Project at the Sanger Institute. Data submitted to COSMIC are reviewed by an expert panel. In VarSeq, you will see the somatic mutation frequencies, tumor subtypes and relevant histology along with links to published papers supporting the findings.
Data contained in COSMIC is presented in two annotation groups, a summarized version for quick filtering and a more detail characterization of each mutation (Figure 2). The Summary group provides information regarding Mutation ID and Gene names, with the reported change in the coding sequence and amino acids and cancer sites. The full COSMIC 71 track contains additional gene and transcript IDs, histological classification, mutation description/zygosity/somatic status, functional predictions, and study data.



Fig 2. All fields contained in VarSeq’s Summary of COSMIC 71 mutations and complete COSMIC Mutations Left Aligned annotations.
See below (Figure 3) a common filter card that you may have seen in our VarSeq demos. It shows a basic filter chain that begins with 140,714 variants but has them reduced to 449 that exist in COSMIC.
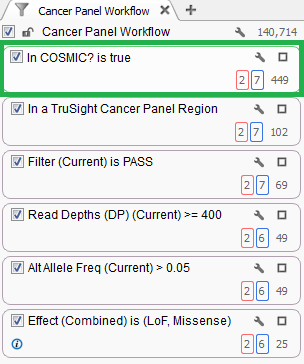
Fig 3. This ‘In COSMIC?’ filter card can quickly isolate only variants in the COSMIC database.
ICGC
COSMIC adds a huge amount of data to the investigation of somatic variants, but another annotation added to VarSeq sets a new standard to what a large cancer database should look like. The International Cancer Genome Consortium, or ICGC, aims to capture the full spectrum of mutations that occur in cancer and their effects in transcriptional regulation. The current version (V25) consists of:
- Cancer projects: 76
- Cancer Primary sites: 21
- Donors with molecular data in DCC: 17,570
- Total Donors: 20,343
- Simple somatic mutations: 63,480,214
- Mutated genes: 57,753
ICGC aim to cover 50 different cancer types, each with 500 matched tumor/normal samples for each type. That’s 50,000 total genomes. With over 20,000 donors to date and over 47 million records encompassing over 57,000 mutated genes, ICGC brings an extreme amount of data to annotate against in VarSeq.
ICGC clearly leads in the ability to profile the prevalence and types of cancers that occur for a given mutation and will no doubt become an indispensable tool in the interpretation of somatic mutations in clinical genomics. The ICGC facilitates communication among the members and provides a forum for coordination with the objective of maximizing efficiency among the scientists working to understand, treat, and prevent these diseases. Figure 4 gives a view of the ICGC content available in VarSeq. In addition to listing some mutation and project identifiers, ICGC in VarSeq also gives more project depth. Including fields such as the numbers of affected donors with a total number of samples in project, as well as the associated affected donor frequency.

Fig 4. View of ICGC annotation in VarSeq
Golden Helix has a long-standing background in providing high-quality annotation options for somatic variant interpretation. The annotations mentioned in this blog are a few of an extensive list available to users conducting cancer-related analysis. The abundance of study, publication, and clinical information in these example annotations is easily accessed not only in VarSeq’s table view but also through various hyperlinks to reputable sites. In part three of this annotation blog series, I will focus on functional prediction, gene tracks, and frequency databases.